
硬件是推进自然语言处理的关键吗?
2021年2月16日通过安东尼奥Anzaldua Jr。麻省理工学院(MIT)的研究人员发明了一种名为SpAtten的基于算法的架构,可以减少自然语言处理(NLP)系统中的注意力计算和记忆访问。
如果我们认为学习一门新语言很困难,那么想象一下硬件和软件工程师在使用cpu和gpu处理大量语言数据时所面临的挑战。自然语言处理(NLP)试图弥合语言和计算之间的这种差距。
最近,麻省理工学院宣布,他们的研究人员已经设计了一个NLP系统这种方法关注的是语音中更相关的关键词,而不是对句子中的所有词给予同等的权重和计算能力。
据研究小组称,这一发展不仅说明了软件NLP算法的关键作用,以及健壮的处理器承担现代自然语言处理系统中涉及的大量数据计算。
什么是自然语言处理?
由于冗余的出现,例如副词、冠词和介词,人类的语言很难处理和分析。自然语言处理的工作是将人类语言简化并翻译成计算机可以理解的语言。
人类语言中许多冗余的问题是,机器也经常依赖它们来确定输入句子的积极或消极情绪。为了解决哪个部分或“位”是不必要的,NLP利用它的注意机制来缩小数据串中的字符,而不失去其重要性。例如,术语“失败的程序”被缩短或修剪通过注意机制,将其分析为“失败程序”。
目前的自然语言处理系统无法处理具有复杂移动和低运算强度的多个数据分支,这导致了更少的内存访问和更慢的计算。
麻省理工学院的研究人员表示,他们做到了设计了一个叫做斯帕滕的系统这可以消除实时计算中不必要的数据,专注于关键字并预测句子中接下来的单词,而不会影响性能、效率和内存访问。

麻省理工学院的SpAtten中使用的句子分析模型可以消除语言中不重要的部分,同时仍然保留单词的本质,从而确定一个积极或消极的结果。图片由麻省理工学院
SpAtten的软件和硬件架构
当处理大量数据装入一个源时,进程中断问题是常见的。目前的NLP注意力机制在能力、处理速度和计算能力方面都面临着一些挑战。
麻省理工学院的SpAtten使用三种算法优化来减少计算和内存访问,同时提高整体性能:级联令牌剪枝、级联头部剪枝和注意力输入的渐进量化。
级联剪枝是一种实时消除计算中不必要的数据位而不会延迟的技术。一个令牌一个关键词在一个句子中找到,而一个头指的是计算分支的注意机制遵循来确定将来的词。这些算法都依赖于输入,并且对所有输入实例都是自适应的。
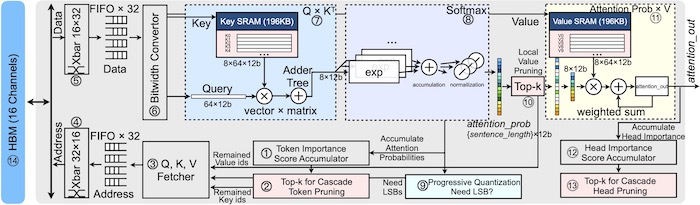
SpAtten的架构允许DRAM访问减少到原来的10倍,计算减少到原来的3.8倍。图片由麻省理工学院
麻省理工学院的研究人员添加了一个具有完全流水线数据的并行硬件架构,以补充预期的软件,以协助实时级联。SpAtten的硬件可以通过片上位宽转换器提高带宽利用率,该转换器将获取的比特分拆为最高有效比特(MSBs)和最低有效比特(lbs)。
片内SRAM有助于内存,它保存了可在多个查询中重用的精简令牌——释放CPU上的内存。
与谷歌的BERT和OpenAI的GPT-2比较
两种不同的任务定义了当前的自然语言处理模型:区分性和生成性。判别任务包括句子级分类和回归,这些任务有助于模型区分某一数据是否通过。生成任务处理分析数据的分布,并允许模型预测序列中的下一个单词。
谷歌的伯特是一种基于任务的鉴别模型,需要总结给定的输入以作出预测。随着更复杂、更大的数据流量的逼近,这些类型的模型将经历更高的延迟。
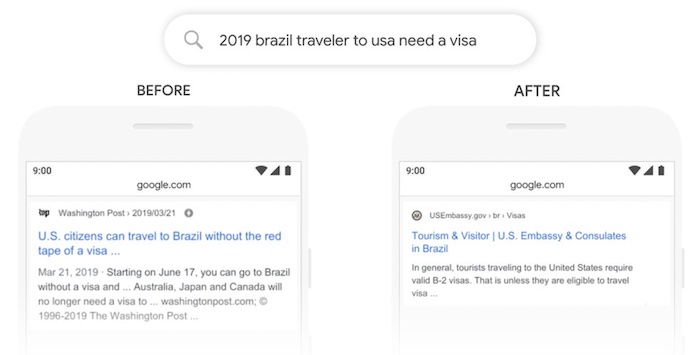
谷歌的BERT在使用中的图像,帮助搜索引擎证明更好的结果。图片由谷歌
一个基于任务的生成模型的例子是OpenAI的GPT-2,在汇总输入信息以生成新令牌之后,会出现延迟和性能问题。
这两种模型一次只能处理一个标记,而不是一个完整的句子,这使得注意机制在总延迟中占了大约50%。麻省理工学院的SpAtten结合了NLP算法和专门为注意力机制设计的外部硬件。这种组合减轻了标准cpu在运行GPT-2或BERT时面临的巨大功耗。
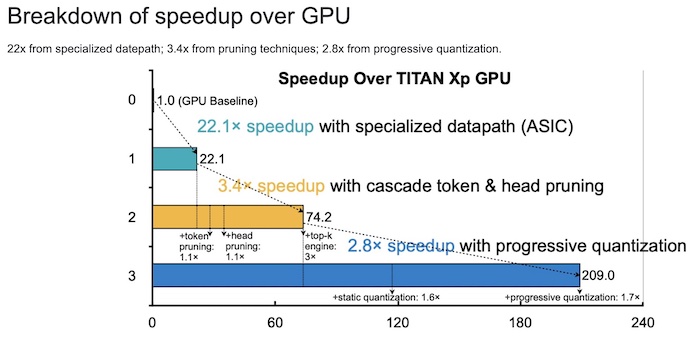
斯帕滕的GPU加速故障。图片由麻省理工学院
MIT解释说,由于软件和硬件的并行化以及流水线的数据路径,SpAtten的延迟更低。该模型还可以通过级联剪枝和累进量化减少计算量和DRAM访问,从而降低能耗。
飞溅可以用于移动设备吗?
麻省理工承认,由于能耗问题,SpAtten(目前的状态)不适合小型物联网设备;SpAtten耗电量为8.3 W,大多数移动设备的耗电量不超过5 W。
然而,通过级联修剪来缩短输入,开发人员可以使用处理时间更短、功耗更低的较小模型。这一低功耗的目标可能是实现移动应用交互对话的下一个步骤,同时仍然维护一个更强的关注机制。
尽管NLP已经从它开始的地方走了很长一段路,但它仍然离完美还有很长的路要走。麻省理工学院表示,推进这项技术的关键——尤其是在功率和延迟方面——在于同时改进软件和硬件。





