
从软件优先的角度构建的AI硬件:Groq灵活的硅架构
2019年12月03日通过马吉德艾哈迈德拥有软件根基的半导体初创公司Groq开发了一种具有独特架构的新处理单元,为人工智能加速提供推理解决方案。
半导体行业的初创公司通常是由硬件工程师创建的,他们开发了一个硅架构,然后想出如何为特定的硬件绘制软件。
这是一家成立于人工智能(AI)时代的芯片初创公司的故事,这家公司拥有软件DNA。
从软件的角度来研究人工智能硬件
Groq成立于2016年,由一群想从软件方面解决人工智能问题的软件工程师创建。当他们在解决这个问题时没有任何预先设想AI架构应该是什么样子,他们就能够创建一个可以映射到不同AI模型的架构。
该公司专注于数据中心和自动驾驶汽车的推理市场,其第一款产品是PCIe插卡,Groq为其设计了ASIC和AI加速器,并开发了软件堆栈。
这个硬件的一部分是他们所称的TSP或张量流处理器。上个月,Groq宣布他们的TSP体系结构能够每秒运算一千万亿次(1000,000,000,000,000)。

Groq的张量流处理器(TSP)显示在PCIe板上,目前Mountain View提供。图片由Groq提供。
TSP体系结构利用了提高的计算效率,允许比当前的gpu和cpu更大的灵活性,以及更小的硅足迹。
AI半导体器件的独特硅结构
首席运营官阿德里安•门德斯(Adrian Mendes)表示,除了软件根基,Groq的另一个不同之处在于它的硅架构。Groq AI半导体器件的核心芯片设计与多核gpu或fpga中常用的流水线工艺非常不同。
它从一开始的发展方式是,它从编译器开始,所以设计者可以看到不同的机器学习(ML)模型是什么样子的,并优化它们的结果。在那里,他们可以在高度灵活的架构上开发硬件。
Groq声称这种硅架构有三个明显的优势:
- AI模型的灵活性
- 通过基于软件的优化对即将到来的AI模型进行未来验证
- 更多有关编制需求的资料
使用高度灵活的AI架构,设计师不必将其映射到renet -50或long -term memory (LSTM)等神经网络。相反,他们可以采用这种足够通用的体系结构,并具有可扩展性,以适应研究社区创建的新模型。随后,无需对硬件进行任何更改,就可以针对这些模型优化petaop的架构。
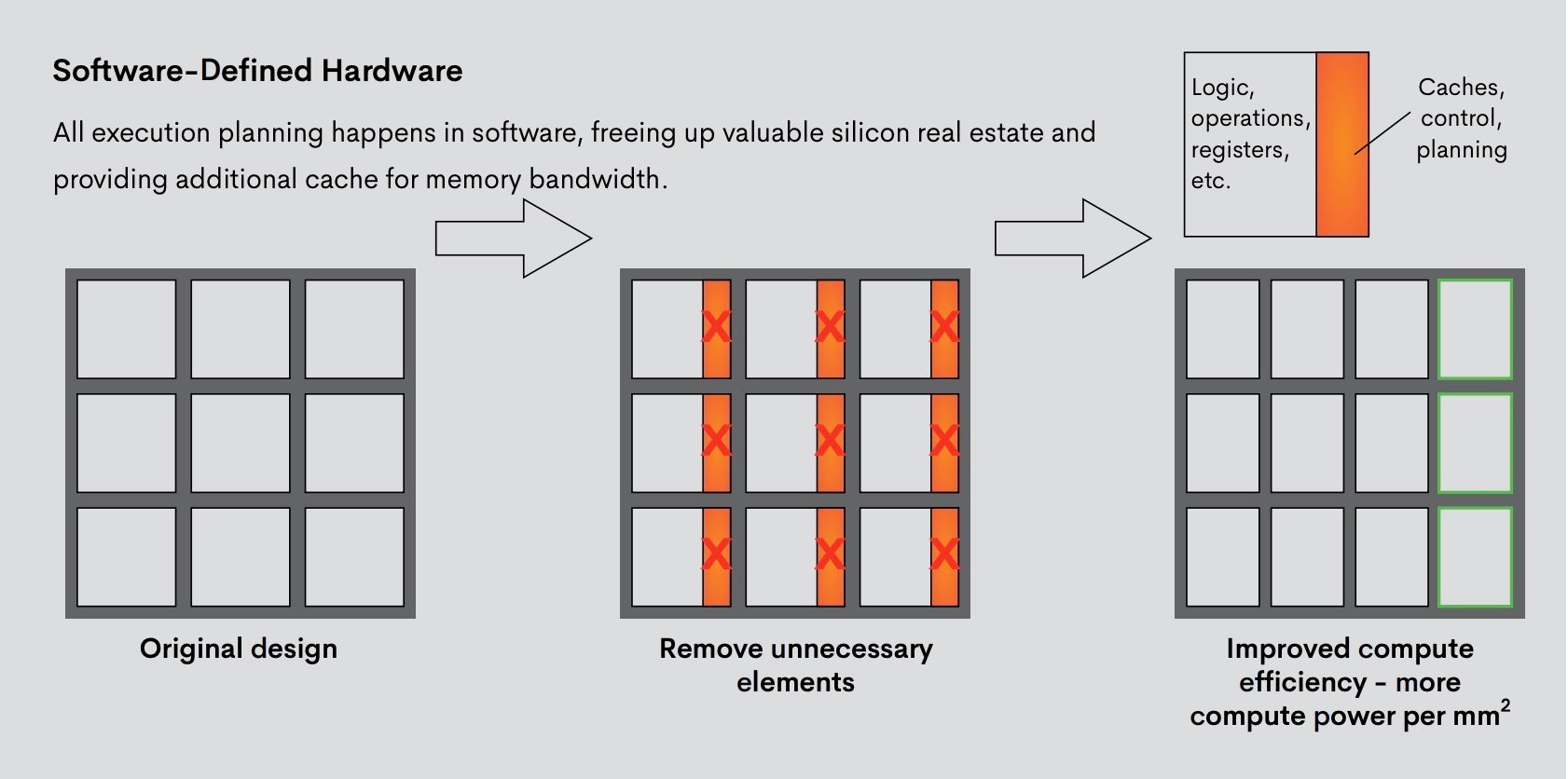
一个表示Groq的软件定义的硬件概念,以提高计算效率。图片来自Groq的白皮书。张量流架构为计算密集型工作负载提供了无与伦比的性能”
换句话说,这是一种硬件,可以容纳我们还没见过的AI模型,优化可以在软件堆栈中完成。除了灵活性,AI芯片为不同的AI模型提供了高推理吞吐量和非常低的延迟。
第三个重要的特征是,芯片是确定性的,直到循环计数。正如门德斯解释的那样,这意味着,当一个机器学习工程师将一个程序推进编译器时,他或她将立即知道该程序将运行多久。
因此,工程师可以了解他们的功耗将会是多少,他们是否想要优化延迟或吞吐量,以及如何改变这些不同参数的设计。他们可以在编译期间(不是很长)完成这些工作。
现在将这个方法与工程师必须运行硬件一千次的方法进行比较,看看延迟是什么。这总结了芯片决定论的好处。
谷歌TPU谱系
如果术语“张量”在人工智能硬件环境中听起来很熟悉,这可能是因为谷歌介绍了张量处理单元(TPU)作为一个概念在2016年。这个ASIC(应用专用集成电路)是为人工智能设计的,允许在云上进行资源饥渴的人工智能处理。
谷歌的tpu已经为人工智能加速设定了几个里程碑。2018年,例如,谷歌展示了他们的第三代tpu通过人工智能程序调用真实的餐馆和发廊预约代表一个用户没有线的另一端上的人是否能够告诉他们说机器。这个项目被命名为谷歌双。
Grog从谷歌的工作中直接受益,其联合创始人兼首席执行官Jonathan Ross帮助谷歌的架构团队开发tpu。

乔纳森•罗斯,Groq的首席执行官和联合创始人。图片由Groq提供
Ross参与了谷歌在开发tpu方面的研究计划,包括a2017年tpu在数据中心应用中的应用研究其重点是开发卷积神经网络(CNNs)的架构。
这一背景为Ross与Groq的合作奠定了基础,因为Groq在人工智能加速硬件的硅架构方面取得了长足进展。
你对人工智能加速有什么经验?你在云端使用过谷歌的TPUs吗?请在下面的评论中分享你对这项正在发展的技术的看法。
